Tu VPS va lento. O peor: no responde. ¿Por dónde empezar? El diagnóstico sistemático es la diferencia entre resolver el problema en minutos o pasarte horas dando palos de ciego.
Esta guía te enseña el proceso paso a paso para identificar y resolver los problemas más comunes en servidores Linux.
El proceso de diagnóstico
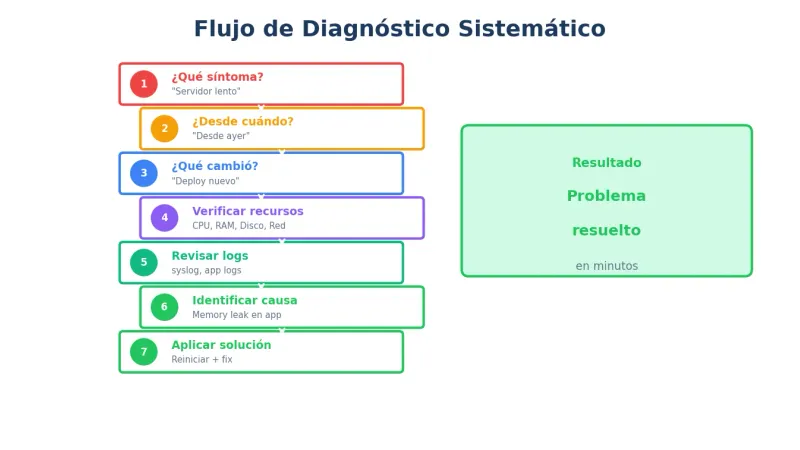
Metodología sistemática
1. ¿Cuál es el síntoma exacto?
↓
2. ¿Desde cuándo ocurre?
↓
3. ¿Qué cambió antes del problema?
↓
4. Verificar recursos (CPU, RAM, disco, red)
↓
5. Revisar logs
↓
6. Identificar causa raíz
↓
7. Aplicar solución
↓
8. Verificar que funcionaPreguntas clave
| Pregunta | Por qué importa |
|---|---|
| ¿Qué síntoma exacto? | ”Va lento” no es útil, “tarda 10s en cargar” sí |
| ¿Desde cuándo? | Delimita el problema |
| ¿Qué cambió? | Actualización, nuevo código, más tráfico |
| ¿Afecta a todo o solo algo? | Ayuda a aislar el componente |
Herramientas esenciales
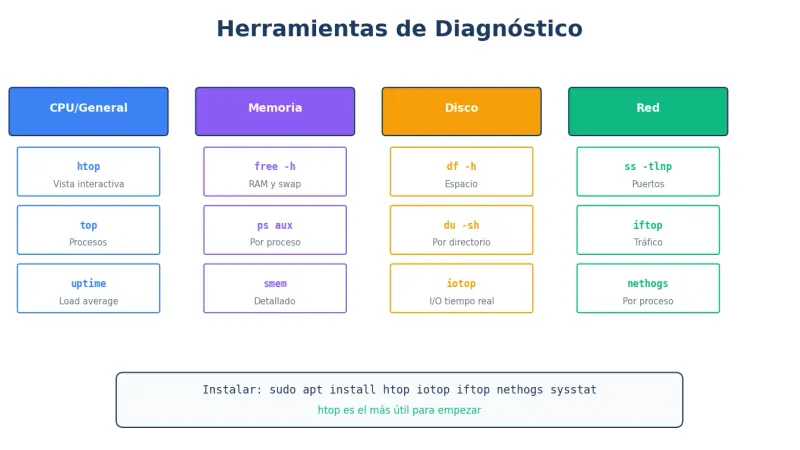
Vista rápida del sistema
# Estado general en un vistazo
htophtop muestra:
- CPU por core
- RAM usada/disponible
- Procesos ordenados por uso
- Load average
Comandos básicos
| Comando | Qué muestra |
|---|---|
htop | Vista general interactiva |
top | Procesos (viene instalado) |
free -h | Memoria RAM |
df -h | Espacio en disco |
iostat | I/O de disco |
netstat -tlnp | Puertos y conexiones |
ss -s | Resumen de sockets |
dmesg -T | Mensajes del kernel |
Instalar herramientas
sudo apt install -y htop iotop iftop nethogs sysstatDiagnóstico de CPU
Síntomas de problema de CPU
- Servidor muy lento
- Comandos tardan en ejecutar
- Load average alto
Verificar uso de CPU
# Load average
uptime
# Salida: load average: 2.50, 2.30, 2.10
# Los 3 números = últimos 1, 5, 15 minutos
# Regla: si > número de cores = sobrecargado# Ver cores disponibles
nproc
# Si tienes 2 cores y load > 2.0 = problema# Qué proceso consume más
top -o %CPU
# o
ps aux --sort=-%cpu | head -10Causas comunes
| Causa | Solución |
|---|---|
| Proceso desbocado | Kill o reiniciar servicio |
| Ataque/spam | Firewall, fail2ban |
| Código ineficiente | Optimizar aplicación |
| Falta de recursos | Escalar VPS |
Soluciones
# Identificar proceso problemático
top -o %CPU
# Matar proceso específico
kill -9 PID
# Reiniciar servicio
sudo systemctl restart nginx
# Limitar CPU de un proceso (temporal)
cpulimit -p PID -l 50Diagnóstico de RAM
Síntomas de problema de memoria
- OOM Killer mata procesos
- Swap muy usado
- Aplicaciones crashean
Verificar memoria
# Resumen de memoria
free -h total used free shared buff/cache available
Mem: 3.8Gi 2.1Gi 200Mi 50Mi 1.5Gi 1.4Gi
Swap: 2.0Gi 500Mi 1.5GiImportante: available es lo que realmente puedes usar (free + buff/cache liberables).
# Procesos ordenados por memoria
ps aux --sort=-%mem | head -10
# Memoria por proceso
smem -tkCausas comunes
| Causa | Solución |
|---|---|
| Memory leak | Reiniciar aplicación, actualizar |
| Demasiados procesos | Reducir workers |
| Falta de RAM | Escalar o añadir swap |
| Caché mal configurada | Ajustar límites |
Soluciones
# Ver qué OOM killer mató
dmesg | grep -i "killed process"
# Limpiar caché (temporal, no recomendado habitualmente)
sync; echo 3 > /proc/sys/vm/drop_caches
# Añadir swap si no tienes
sudo fallocate -l 2G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfileDiagnóstico de disco
Síntomas de problema de disco
- “No space left on device”
- Escrituras muy lentas
- Aplicaciones no pueden guardar datos
Verificar espacio
# Uso por partición
df -h
# Qué directorio ocupa más
du -sh /* 2>/dev/null | sort -hr | head -10
# Archivos más grandes
find / -type f -size +100M -exec ls -lh {} \; 2>/dev/nullVerificar I/O
# I/O en tiempo real
iotop
# Estadísticas de disco
iostat -x 1 5Métricas clave:
%util> 80% = disco saturadoawait> 10ms = latencia alta
Causas comunes
| Causa | Solución |
|---|---|
| Logs enormes | Rotar logs, limpiar antiguos |
| Backups acumulados | Eliminar backups viejos |
| Archivos temporales | Limpiar /tmp |
| Base de datos grande | Optimizar, archivar |
Soluciones
# Limpiar logs antiguos
sudo journalctl --vacuum-time=7d
# Limpiar apt cache
sudo apt clean
# Encontrar y eliminar logs grandes
find /var/log -name "*.log" -size +100M
# Rotar logs manualmente
sudo logrotate -f /etc/logrotate.confDiagnóstico de red
Síntomas de problema de red
- Conexiones lentas
- Timeouts
- No se puede conectar
Verificar conectividad
# ¿Hay internet?
ping -c 3 8.8.8.8
# ¿DNS funciona?
ping -c 3 google.com
# ¿Puerto específico accesible?
nc -zv tudominio.com 443Verificar puertos y conexiones
# Puertos escuchando
ss -tlnp
# Conexiones activas
ss -s
# Conexiones por estado
netstat -an | awk '/^tcp/ {print $6}' | sort | uniq -c | sort -rnVerificar ancho de banda
# Tráfico en tiempo real
iftop -i eth0
# Tráfico por proceso
nethogs eth0
# Estadísticas de interfaz
ip -s link show eth0Causas comunes
| Causa | Solución |
|---|---|
| Firewall bloqueando | Revisar ufw/iptables |
| Servicio no corriendo | Iniciar servicio |
| Puerto incorrecto | Verificar configuración |
| Demasiadas conexiones | Optimizar, escalar |
| DDoS | Cloudflare, mitigación |
Soluciones
# Verificar firewall
sudo ufw status verbose
# Abrir puerto
sudo ufw allow 80/tcp
# Verificar si servicio escucha
sudo lsof -i :80
# Reiniciar servicio
sudo systemctl restart nginxDiagnóstico de servicios
Verificar estado de servicios
# Estado de un servicio
sudo systemctl status nginx
# Ver servicios fallidos
sudo systemctl --failed
# Logs de un servicio
sudo journalctl -u nginx -n 50 --no-pager
# Logs en tiempo real
sudo journalctl -u nginx -fServicios comunes y sus logs
| Servicio | Comando status | Logs |
|---|---|---|
| Nginx | systemctl status nginx | /var/log/nginx/error.log |
| Apache | systemctl status apache2 | /var/log/apache2/error.log |
| MySQL | systemctl status mysql | /var/log/mysql/error.log |
| PHP-FPM | systemctl status php8.2-fpm | /var/log/php8.2-fpm.log |
Soluciones
# Reiniciar servicio
sudo systemctl restart nginx
# Recargar configuración (sin downtime)
sudo systemctl reload nginx
# Ver por qué falló
sudo journalctl -u nginx -n 100
# Verificar configuración antes de reiniciar
sudo nginx -tRevisar logs del sistema
Logs principales
# Logs del sistema
sudo tail -100 /var/log/syslog
# Logs de autenticación
sudo tail -100 /var/log/auth.log
# Mensajes del kernel
dmesg -T | tail -50
# Todos los logs recientes
sudo journalctl -p err -n 50Buscar errores específicos
# Errores en logs
grep -i error /var/log/syslog | tail -20
# OOM kills
dmesg | grep -i "killed process"
# Errores de disco
dmesg | grep -i "error\|fail"
# Intentos de login fallidos
grep "Failed password" /var/log/auth.log | tail -20Checklist de diagnóstico rápido
Cuando el servidor va lento
# 1. Vista general
htop
# 2. Load average
uptime
# 3. Memoria
free -h
# 4. Disco
df -h
# 5. Procesos problemáticos
ps aux --sort=-%cpu | head -5
ps aux --sort=-%mem | head -5Cuando no responde un servicio
# 1. ¿Está corriendo?
sudo systemctl status servicio
# 2. ¿Puerto abierto?
ss -tlnp | grep PUERTO
# 3. ¿Firewall bloquea?
sudo ufw status
# 4. ¿Logs dicen algo?
sudo journalctl -u servicio -n 50Cuando no puedes conectar por SSH
- Prueba desde otro dispositivo
- Usa consola VNC del proveedor
- Verifica que sshd está corriendo
- Revisa firewall
- Comprueba fail2ban no te bloqueó
Script de diagnóstico automático
#!/bin/bash
# /root/scripts/diagnostico.sh
echo "=========================================="
echo "DIAGNÓSTICO RÁPIDO DEL VPS"
echo "Fecha: $(date)"
echo "=========================================="
echo ""
echo "=== SISTEMA ==="
echo "Hostname: $(hostname)"
echo "Uptime: $(uptime -p)"
echo "Load: $(uptime | awk -F'load average:' '{print $2}')"
echo ""
echo "=== CPU ==="
echo "Cores: $(nproc)"
echo "Uso actual:"
mpstat 1 1 | tail -1
echo ""
echo "=== MEMORIA ==="
free -h
echo ""
echo "=== DISCO ==="
df -h | grep -E '^/dev/'
echo ""
echo "=== TOP 5 PROCESOS (CPU) ==="
ps aux --sort=-%cpu | head -6
echo ""
echo "=== TOP 5 PROCESOS (RAM) ==="
ps aux --sort=-%mem | head -6
echo ""
echo "=== SERVICIOS FALLIDOS ==="
systemctl --failed --no-pager
echo ""
echo "=== PUERTOS ESCUCHANDO ==="
ss -tlnp | grep LISTEN
echo ""
echo "=== ÚLTIMOS ERRORES ==="
journalctl -p err -n 10 --no-pager
echo ""
echo "=========================================="
echo "Diagnóstico completado"
echo "=========================================="chmod +x /root/scripts/diagnostico.sh
./diagnostico.shPreguntas frecuentes
¿Qué es el load average y cuándo es problemático?
Load average indica cuántos procesos esperan CPU. Si es mayor que el número de cores de forma sostenida, hay problema. Con 2 cores, load > 2.0 sostenido es preocupante.
¿Por qué free muestra poca memoria libre pero el servidor funciona bien?
Linux usa RAM libre para caché de disco. Mira 'available', no 'free'. Si available es bajo, entonces sí tienes problema de memoria.
¿Cómo sé si el problema es del VPS o de mi aplicación?
Si los recursos del sistema están bien (CPU < 80%, RAM available > 20%, disco < 90%), el problema probablemente está en tu aplicación o configuración.
¿Qué hago si no puedo conectar por SSH?
Usa la consola VNC/web de tu proveedor de VPS. Desde ahí puedes verificar si sshd está corriendo, si el firewall bloquea, o si fail2ban te baneó.
¿Cada cuánto debo revisar el estado del VPS?
Idealmente con monitorización automática (Netdata, alertas). Manualmente, una revisión semanal rápida es buena práctica.
Nuestra recomendación
Para diagnóstico rápido:
- htop para vista general
- Script de diagnóstico automático
- Alertas automáticas con Netdata
Para problemas persistentes:
- Revisa logs sistemáticamente
- Identifica el componente afectado
- Busca qué cambió antes del problema
¿Problemas que no puedes resolver? La administración gestionada de Avantys incluye monitorización proactiva y resolución de incidencias 24/7.
Conclusión
El diagnóstico sistemático es una habilidad que se desarrolla con práctica. Empieza siempre por los recursos básicos (CPU, RAM, disco, red) y ve profundizando según los síntomas.
El 80% de los problemas se resuelven con los comandos básicos de esta guía.
¿Necesitas un VPS fiable con soporte? Explora los VPS de Avantys con monitorización y soporte incluidos.
¿Quieres que lo hagamos por ti?
En Avantys gestionamos tu web, hosting y crecimiento digital de punta a punta. Tú a lo importante.


