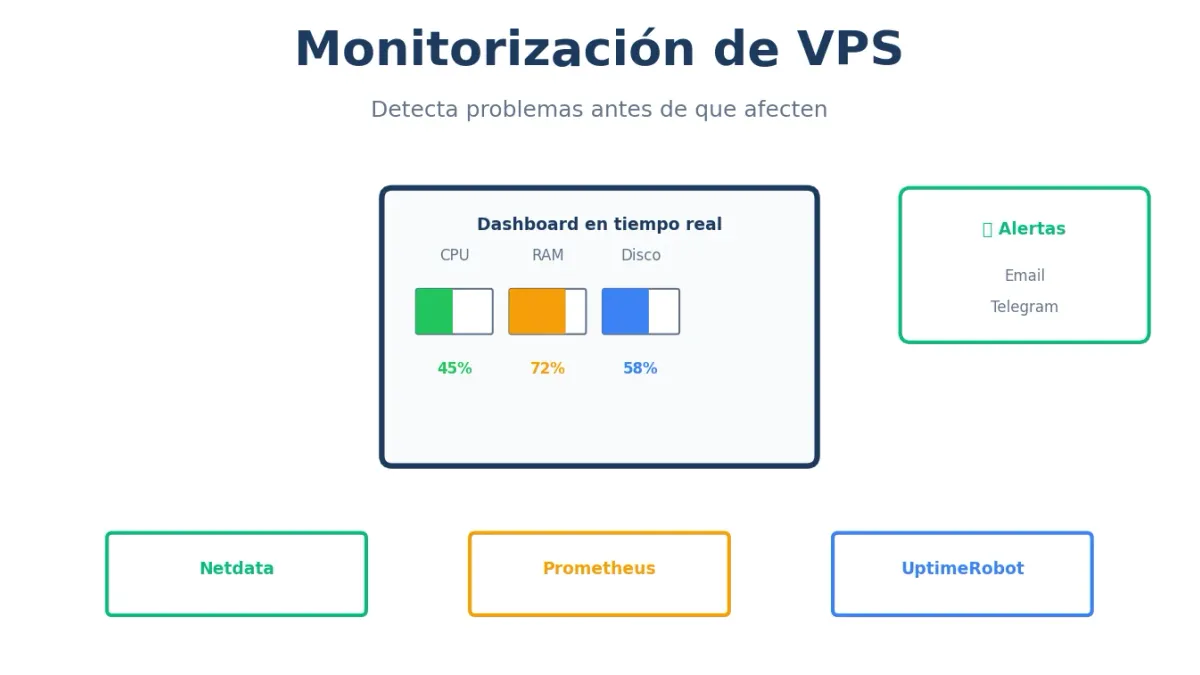
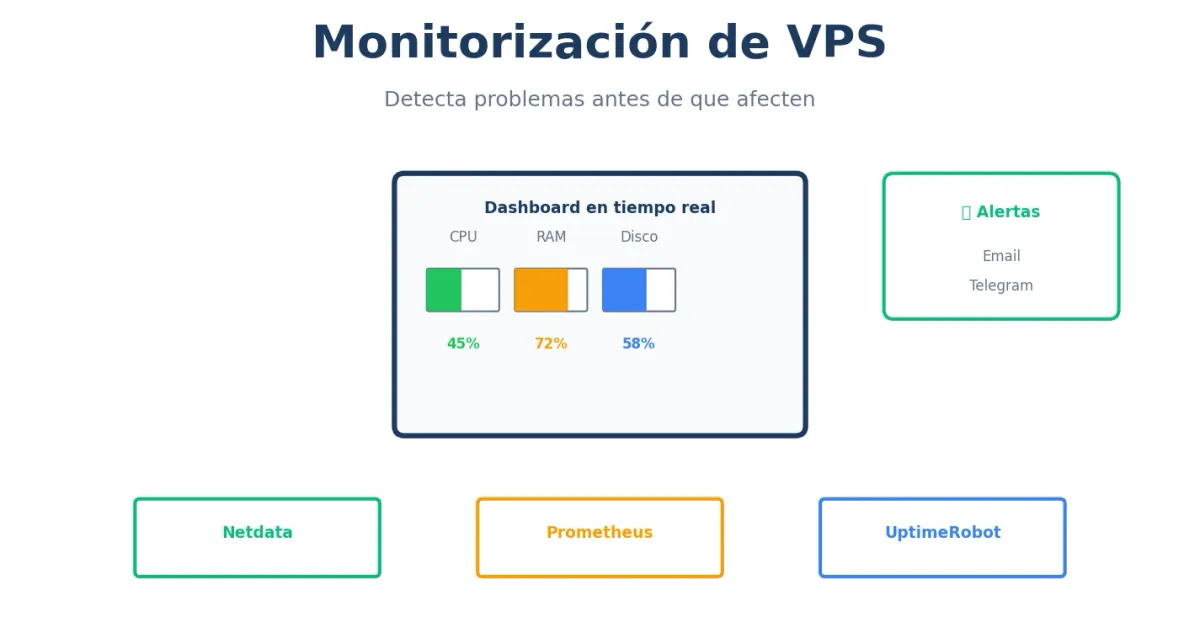
¿Cómo sabes si tu VPS está bien? ¿Esperas a que los usuarios se quejen? La monitorización te permite detectar problemas antes de que afecten a nadie.
Esta guía te enseña a implementar monitorización completa con alertas automáticas.
Por qué monitorizar
Sin monitorización vs Con monitorización
| Sin monitorización | Con monitorización |
|---|---|
| Te enteras cuando falla | Detectas antes de fallar |
| Usuarios se quejan | Alertas proactivas |
| Apagar fuegos | Prevención |
| Sin datos para decidir | Métricas para optimizar |
| ”¿Por qué está lento?" | "CPU al 85%, necesita escalar” |
Métricas esenciales
| Métrica | Por qué importa |
|---|---|
| CPU | Capacidad de procesamiento |
| RAM | Memoria disponible |
| Disco | Espacio y velocidad I/O |
| Red | Ancho de banda y latencia |
| Procesos | Servicios corriendo |
| Uptime | Disponibilidad |
Herramientas de monitorización
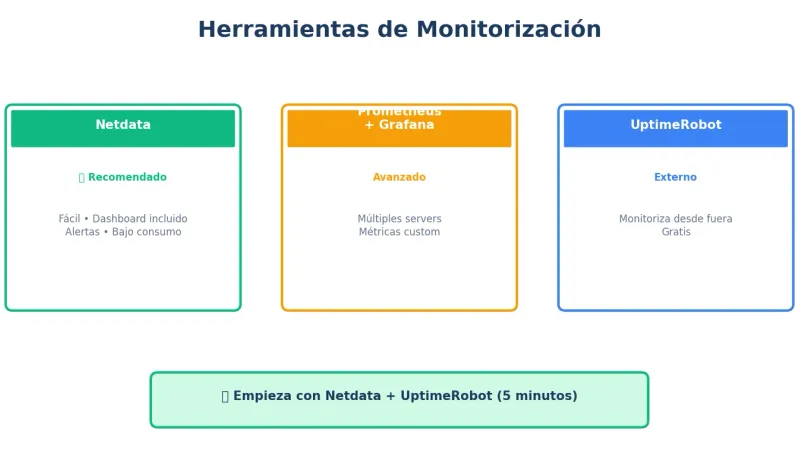
Comparativa rápida
| Herramienta | Complejidad | Recursos | Ideal para |
|---|---|---|---|
| htop | Muy fácil | Mínimos | Vista rápida manual |
| Netdata | Fácil | Bajos | VPS individual |
| Prometheus + Grafana | Media | Medios | Múltiples servidores |
| Zabbix | Alta | Altos | Infraestructura grande |
| UptimeRobot | Muy fácil | Externos | Uptime básico |
Netdata: La opción recomendada
Por qué Netdata
- Instalación en 1 minuto
- Dashboard hermoso incluido
- Alertas preconfiguradas
- Consume pocos recursos
- Gratis y open source
Instalación
# Instalación automática
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
# O manualmente en Ubuntu/Debian
sudo apt install netdata -yAcceder al dashboard
# Por defecto en puerto 19999
http://IP_DEL_VPS:19999
# Si tienes firewall
sudo ufw allow 19999/tcpProteger con contraseña (Nginx proxy)
# /etc/nginx/sites-available/netdata
server {
listen 80;
server_name monitor.tudominio.com;
auth_basic "Monitorización";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:19999;
proxy_set_header Host $host;
}
}# Crear usuario y contraseña
sudo apt install apache2-utils -y
sudo htpasswd -c /etc/nginx/.htpasswd admin
# Activar
sudo ln -s /etc/nginx/sites-available/netdata /etc/nginx/sites-enabled/
sudo nginx -t && sudo systemctl reload nginx
# Bloquear acceso directo
sudo ufw delete allow 19999/tcpConfigurar alertas en Netdata
# Editar configuración de alertas
sudo nano /etc/netdata/health.d/cpu.conf# Alerta cuando CPU > 80% por 5 minutos
alarm: cpu_usage_high
on: system.cpu
lookup: average -5m unaligned of user,system
units: %
every: 1m
warn: $this > 80
crit: $this > 95
info: CPU usage is highAlertas por email
# Configurar notificaciones
sudo nano /etc/netdata/health_alarm_notify.conf# Email
SEND_EMAIL="YES"
EMAIL_SENDER="[email protected]"
DEFAULT_RECIPIENT_EMAIL="[email protected]"
# Opcional: Slack, Discord, Telegram...
SEND_SLACK="YES"
SLACK_WEBHOOK_URL="https://hooks.slack.com/services/xxx"# Reiniciar para aplicar
sudo systemctl restart netdataUptimeRobot: Monitorización externa
Para qué sirve
Monitoriza tu web desde fuera. Si tu VPS cae completamente, UptimeRobot te avisa (porque no depende del VPS).
Configuración
- Crea cuenta en uptimerobot.com (gratis)
- Add New Monitor → HTTP(s)
- URL:
https://tudominio.com - Monitoring Interval: 5 minutes
- Alert Contacts: tu email
Qué monitorizar
✓ Página principal (HTTPS)
✓ API endpoint crítico
✓ Panel de admin
✓ Puerto SSH (si quieres)Prometheus + Grafana (Avanzado)
Cuándo usarlo
- Múltiples servidores
- Métricas personalizadas
- Dashboards complejos
- Retención de datos larga
Arquitectura
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ VPS 1 │ │ VPS 2 │ │ VPS 3 │
│ node_export │ │ node_export │ │ node_export │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└───────────────────┼───────────────────┘
│
┌───────▼───────┐
│ Prometheus │
│ (recolecta) │
└───────┬───────┘
│
┌───────▼───────┐
│ Grafana │
│ (visualiza) │
└───────────────┘Instalar Node Exporter (en cada VPS)
# Descargar
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar xvfz node_exporter-*.tar.gz
sudo mv node_exporter-*/node_exporter /usr/local/bin/
# Crear servicio
sudo nano /etc/systemd/system/node_exporter.service[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.targetsudo useradd -rs /bin/false node_exporter
sudo systemctl daemon-reload
sudo systemctl enable --now node_exporter
# Verificar (puerto 9100)
curl localhost:9100/metrics | headInstalar Prometheus (en servidor central)
# Descargar
wget https://github.com/prometheus/prometheus/releases/download/v2.48.0/prometheus-2.48.0.linux-amd64.tar.gz
tar xvfz prometheus-*.tar.gz
sudo mv prometheus-*/prometheus /usr/local/bin/
sudo mv prometheus-*/promtool /usr/local/bin/
# Configurar
sudo mkdir /etc/prometheus /var/lib/prometheus
sudo nano /etc/prometheus/prometheus.ymlglobal:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'nodes'
static_configs:
- targets:
- '10.0.0.1:9100' # VPS 1
- '10.0.0.2:9100' # VPS 2
- '10.0.0.3:9100' # VPS 3# Crear servicio y arrancar
sudo systemctl enable --now prometheusInstalar Grafana
# Ubuntu/Debian
sudo apt install -y apt-transport-https software-properties-common
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
sudo apt update
sudo apt install grafana -y
sudo systemctl enable --now grafana-server
# Acceder en puerto 3000
# Usuario: admin / Contraseña: adminDashboard recomendado
- Grafana → Data Sources → Add Prometheus
- URL:
http://localhost:9090 - Dashboards → Import → ID:
1860(Node Exporter Full)
Alertas automáticas
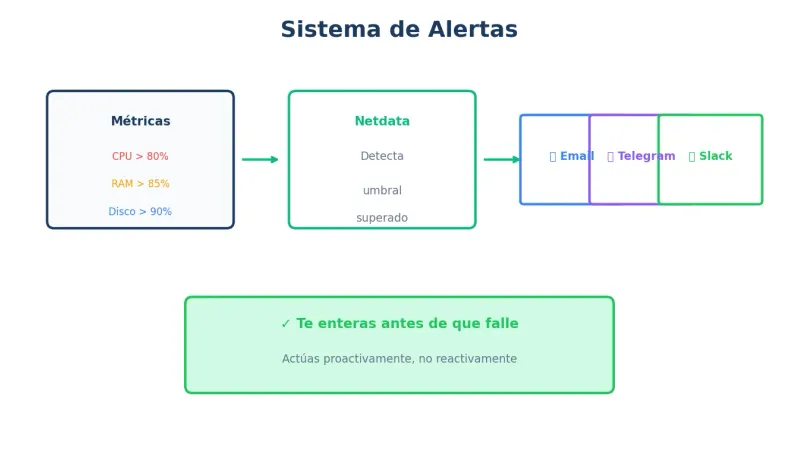
Script de alertas simple
#!/bin/bash
# /root/scripts/alertas.sh
ALERT_EMAIL="[email protected]"
HOSTNAME=$(hostname)
# Umbrales
CPU_THRESHOLD=85
RAM_THRESHOLD=85
DISK_THRESHOLD=85
# CPU
CPU=$(top -bn1 | grep "Cpu(s)" | awk '{print int($2)}')
if [ $CPU -gt $CPU_THRESHOLD ]; then
echo "CPU al ${CPU}% en $HOSTNAME" | mail -s "⚠️ ALERTA CPU" $ALERT_EMAIL
fi
# RAM
RAM=$(free | grep Mem | awk '{printf "%.0f", $3/$2 * 100}')
if [ $RAM -gt $RAM_THRESHOLD ]; then
echo "RAM al ${RAM}% en $HOSTNAME" | mail -s "⚠️ ALERTA RAM" $ALERT_EMAIL
fi
# Disco
DISK=$(df / | tail -1 | awk '{print int($5)}')
if [ $DISK -gt $DISK_THRESHOLD ]; then
echo "Disco al ${DISK}% en $HOSTNAME" | mail -s "⚠️ ALERTA DISCO" $ALERT_EMAIL
fi
# Servicios críticos
for service in nginx mysql php8.2-fpm; do
if ! systemctl is-active --quiet $service; then
echo "$service está caído en $HOSTNAME" | mail -s "🔴 ALERTA: $service DOWN" $ALERT_EMAIL
fi
donechmod +x /root/scripts/alertas.sh
# Cron cada 5 minutos
crontab -e
*/5 * * * * /root/scripts/alertas.shAlertas por Telegram
#!/bin/bash
# /root/scripts/telegram-alert.sh
BOT_TOKEN="tu_bot_token"
CHAT_ID="tu_chat_id"
send_telegram() {
curl -s -X POST "https://api.telegram.org/bot$BOT_TOKEN/sendMessage" \
-d chat_id="$CHAT_ID" \
-d text="$1" \
-d parse_mode="HTML"
}
# Usar en alertas
send_telegram "⚠️ <b>ALERTA</b>: CPU al 90% en $(hostname)"Alertas con ntfy (self-hosted o gratis)
# Enviar alerta
curl -d "CPU al 90% en servidor" ntfy.sh/tu-topic
# En el móvil: instalar app ntfy y suscribirse al topicMonitorización de logs
Journalctl en tiempo real
# Todos los logs
journalctl -f
# Solo errores
journalctl -p err -f
# Servicio específico
journalctl -u nginx -fScript de monitorización de errores
#!/bin/bash
# /root/scripts/check-errors.sh
ERRORS=$(journalctl -p err --since "5 minutes ago" --no-pager | wc -l)
if [ $ERRORS -gt 10 ]; then
journalctl -p err --since "5 minutes ago" --no-pager | \
mail -s "⚠️ $ERRORS errores en últimos 5 min" [email protected]
fiDashboard minimalista con Glances
Instalación
sudo apt install glances -y
# Ejecutar
glances
# Modo web
glances -w
# Acceder en http://IP:61208Glances como servicio
sudo nano /etc/systemd/system/glances.service[Unit]
Description=Glances
After=network.target
[Service]
ExecStart=/usr/bin/glances -w
Restart=always
[Install]
WantedBy=multi-user.targetsudo systemctl enable --now glancesMonitorización de aplicaciones
PHP-FPM status
# En configuración de Nginx
location /fpm-status {
access_log off;
allow 127.0.0.1;
deny all;
fastcgi_pass unix:/run/php/php8.2-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}# Habilitar en php-fpm
sudo nano /etc/php/8.2/fpm/pool.d/www.conf
# pm.status_path = /fpm-status
curl localhost/fpm-statusMySQL status
# Estado rápido
mysqladmin -u root -p status
# Queries lentas
mysql -e "SHOW FULL PROCESSLIST;"
# Variables de rendimiento
mysql -e "SHOW GLOBAL STATUS LIKE 'Slow_queries';"Nginx status
location /nginx-status {
stub_status on;
allow 127.0.0.1;
deny all;
}curl localhost/nginx-statusChecklist de monitorización
## Mínimo viable
☐ Netdata instalado
☐ UptimeRobot configurado
☐ Alertas por email activas
## Recomendado
☐ Alertas por Telegram/Slack
☐ Monitorización de servicios críticos
☐ Dashboard accesible con contraseña
☐ Retención de métricas (7+ días)
## Avanzado
☐ Prometheus + Grafana
☐ Alertas múltiples canales
☐ Monitorización de logs
☐ APM de aplicaciónPreguntas frecuentes
¿Netdata consume muchos recursos?
No, Netdata está optimizado para bajo consumo. Típicamente usa menos de 1% CPU y 100-200MB RAM. Puedes reducir métricas si necesitas aún menos.
¿Puedo monitorizar múltiples VPS con Netdata?
Sí, Netdata Cloud (gratis) te permite ver todos tus servidores en un dashboard unificado. O usa Prometheus+Grafana para control total.
¿Cada cuánto deben ejecutarse las alertas?
Para alertas críticas (servicios caídos), cada 1-2 minutos. Para recursos (CPU, RAM), cada 5 minutos es suficiente para evitar falsos positivos por picos.
¿Necesito monitorización externa además de interna?
Sí. La monitorización interna (Netdata) puede fallar si el servidor cae. UptimeRobot o similar te alerta aunque el servidor esté completamente caído.
¿Cómo evito demasiadas alertas falsas?
Usa promedios en lugar de valores instantáneos (ej: 'CPU > 80% durante 5 minutos'), y ajusta umbrales según el comportamiento normal de tu servidor.
Nuestra recomendación
Para empezar (5 minutos):
- Instala Netdata
- Configura UptimeRobot
- Añade tu email para alertas
Para producción:
- Netdata + alertas Telegram
- Monitorización de servicios críticos
- Dashboard protegido con contraseña
- Revisión semanal de métricas
Conclusión
La monitorización no es opcional, es esencial. Con Netdata puedes tener visibilidad completa de tu VPS en menos de 5 minutos.
No esperes a que algo falle. Configura alertas hoy y duerme tranquilo.
¿Necesitas un VPS con monitorización incluida? Explora los VPS de Avantys con panel de métricas y alertas.
¿Quieres que lo hagamos por ti?
En Avantys gestionamos tu web, hosting y crecimiento digital de punta a punta. Tú a lo importante.


