
Un archivo robots.txt mal configurado puede hacer que tu web desaparezca de Google de la noche a la mañana. El 90% de los sitios web contienen errores en este archivo que afectan directamente a su visibilidad en buscadores. Dos líneas de código incorrectas y todo tu trabajo SEO se esfuma en cuestión de horas.
El robots.txt es uno de los archivos más pequeños de tu web, pero también uno de los más poderosos. Funciona como el portero de tu sitio, indicando a los motores de búsqueda qué pueden rastrear y qué no. Si Google no puede acceder a tus páginas importantes, simplemente no las indexará.
En 2025, con la llegada de los bots de inteligencia artificial como GPTBot y Claude-Web, el robots.txt ha adquirido una nueva dimensión. Ya no solo gestionas crawlers de buscadores tradicionales, sino que decides si tu contenido entrena modelos de IA.
En esta guía aprenderás exactamente cómo funciona este archivo, cómo configurarlo correctamente en WordPress y qué errores críticos debes evitar para que Google rastree las páginas que realmente te importan.
// Índice de contenidos
- ¿Qué es el archivo robots.txt?
- Dónde se ubica y cómo acceder
- Sintaxis básica y directivas principales
- Por qué robots.txt es crucial para el SEO
- Crawl budget: qué es y cómo gestionarlo
- Configurar robots.txt en WordPress
- Errores comunes que destruyen tu SEO
- Robots.txt vs meta noindex: diferencias clave
- Gestionar bots de IA en 2025
- Ejemplos prácticos por tipo de web
- Cómo verificar tu robots.txt
- Preguntas frecuentes
¿Qué es el archivo robots.txt?
El archivo robots.txt es un documento de texto plano ubicado en la raíz de tu sitio web que contiene instrucciones para los robots de los motores de búsqueda. Estas instrucciones indican qué partes de tu web pueden rastrear y cuáles deben ignorar.
Según la documentación oficial de Google Search Central: “El archivo robots.txt indica a los rastreadores de los motores de búsqueda a qué URLs de tu sitio pueden acceder”.
Características fundamentales
| Característica | Descripción |
|---|---|
| Formato | Archivo de texto plano (.txt) |
| Ubicación | Raíz del dominio (ejemplo.com/robots.txt) |
| Tamaño máximo | 500 KB (recomendado por Google) |
| Codificación | UTF-8 |
| Obligatorio | No, pero muy recomendado |
Qué puede y qué no puede hacer
Robots.txt SÍ puede:
- Bloquear el rastreo de URLs o directorios específicos
- Indicar la ubicación del sitemap XML
- Gestionar diferentes crawlers por separado
- Optimizar el presupuesto de rastreo
Robots.txt NO puede:
- Evitar que una página aparezca en Google si tiene enlaces entrantes
- Bloquear el acceso a contenido ya conocido por Google
- Funcionar como medida de seguridad (los bots maliciosos lo ignoran)
- Eliminar páginas ya indexadas
Dónde se ubica y cómo acceder
El archivo robots.txt debe ubicarse siempre en la raíz del dominio, accesible mediante la URL directa:
https://tudominio.com/robots.txtUbicación por tipo de instalación
| Tipo de sitio | Ubicación en servidor |
|---|---|
| WordPress | /public_html/robots.txt |
| Subdominios | Cada subdominio necesita su propio archivo |
| Multisite | Un archivo por cada sitio de la red |
Consejo profesional: Antes de modificar el robots.txt, haz siempre una copia de seguridad del archivo original. Un error puede hacer invisible tu web en cuestión de horas.
Sintaxis básica y directivas principales
El archivo robots.txt utiliza una sintaxis sencilla pero estricta. Un error de sintaxis puede invalidar todas las instrucciones.

Directivas principales
User-agent
Define a qué crawler se aplican las reglas siguientes:
User-agent: * # Todos los bots
User-agent: Googlebot # Solo el bot de GoogleDisallow
Bloquea el acceso a URLs o directorios:
Disallow: /admin/ # Bloquea directorio completo
Disallow: /privado.html # Bloquea archivo específicoAllow
Permite el acceso a una URL dentro de un directorio bloqueado:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpSitemap
Indica la ubicación del mapa del sitio XML:
Sitemap: https://tudominio.com/sitemap_index.xmlPor qué robots.txt es crucial para el SEO
Un archivo robots.txt correctamente configurado impacta directamente en tres áreas fundamentales del SEO técnico.
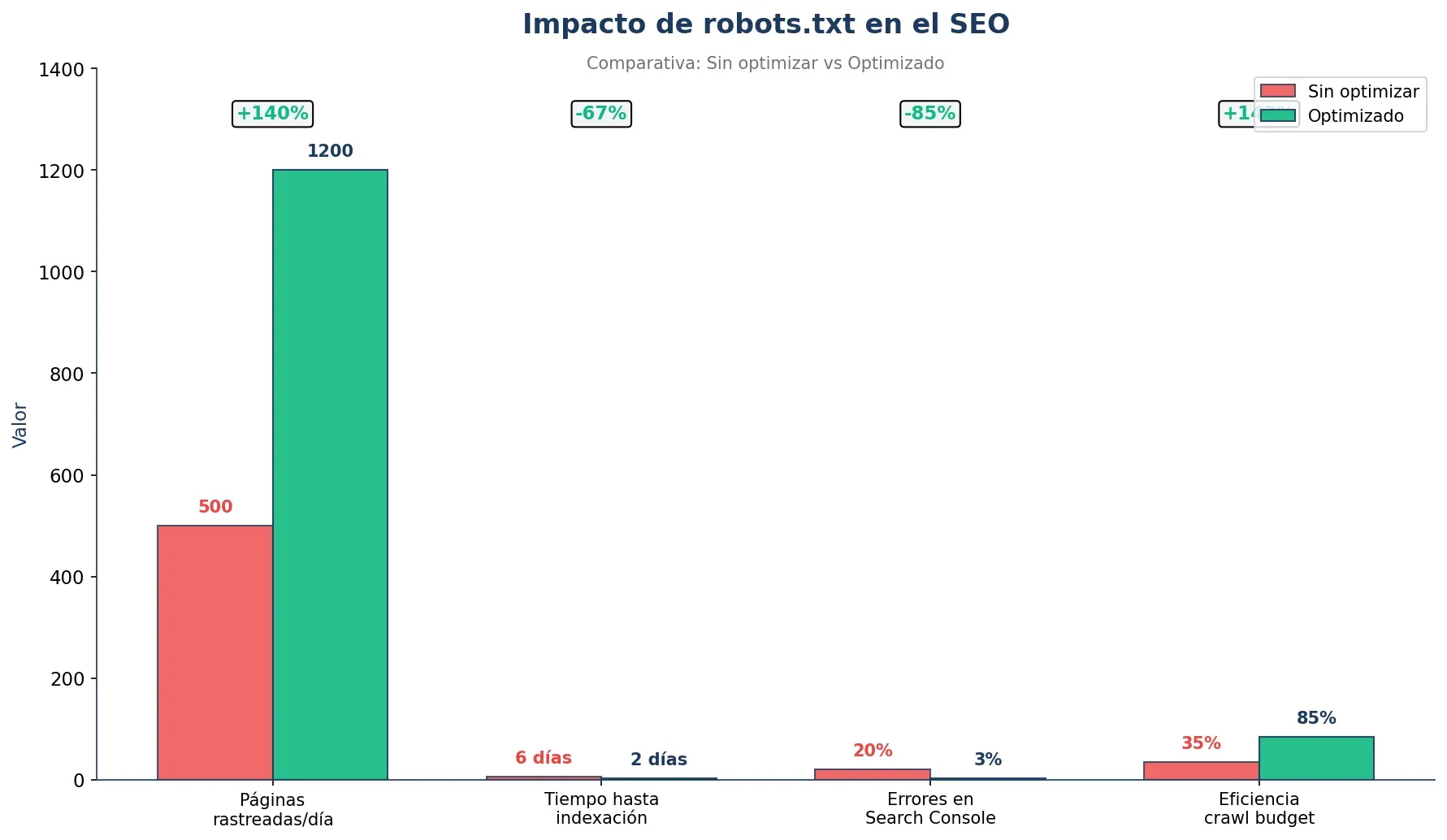
1. Optimización del presupuesto de rastreo
Los motores de búsqueda asignan un número limitado de páginas que rastrearán en un periodo determinado.
2. Priorización de contenido valioso
Al bloquear páginas sin valor SEO, diriges a los crawlers hacia el contenido que realmente quieres posicionar.
3. Reducción de carga en servidor
Limitar el rastreo de bots innecesarios reduce el consumo de recursos del servidor.
Crawl budget: qué es y cómo gestionarlo
El crawl budget o presupuesto de rastreo es el número de páginas que Google rastreará en tu sitio durante un periodo determinado.
Cómo robots.txt optimiza el crawl budget
# Bloquear URLs que consumen crawl budget innecesariamente
User-agent: *
Disallow: /*?orderby=
Disallow: /*?filter=
Disallow: /?s=
Disallow: /search/
Disallow: /*?sessionid=Importante: El crawl budget solo es relevante para sitios con más de 10.000 páginas. Para webs pequeñas, Google rastreará todo sin problemas.
Configurar robots.txt en WordPress
WordPress genera automáticamente un robots.txt virtual básico. Sin embargo, para optimizarlo necesitas crear un archivo físico personalizado.
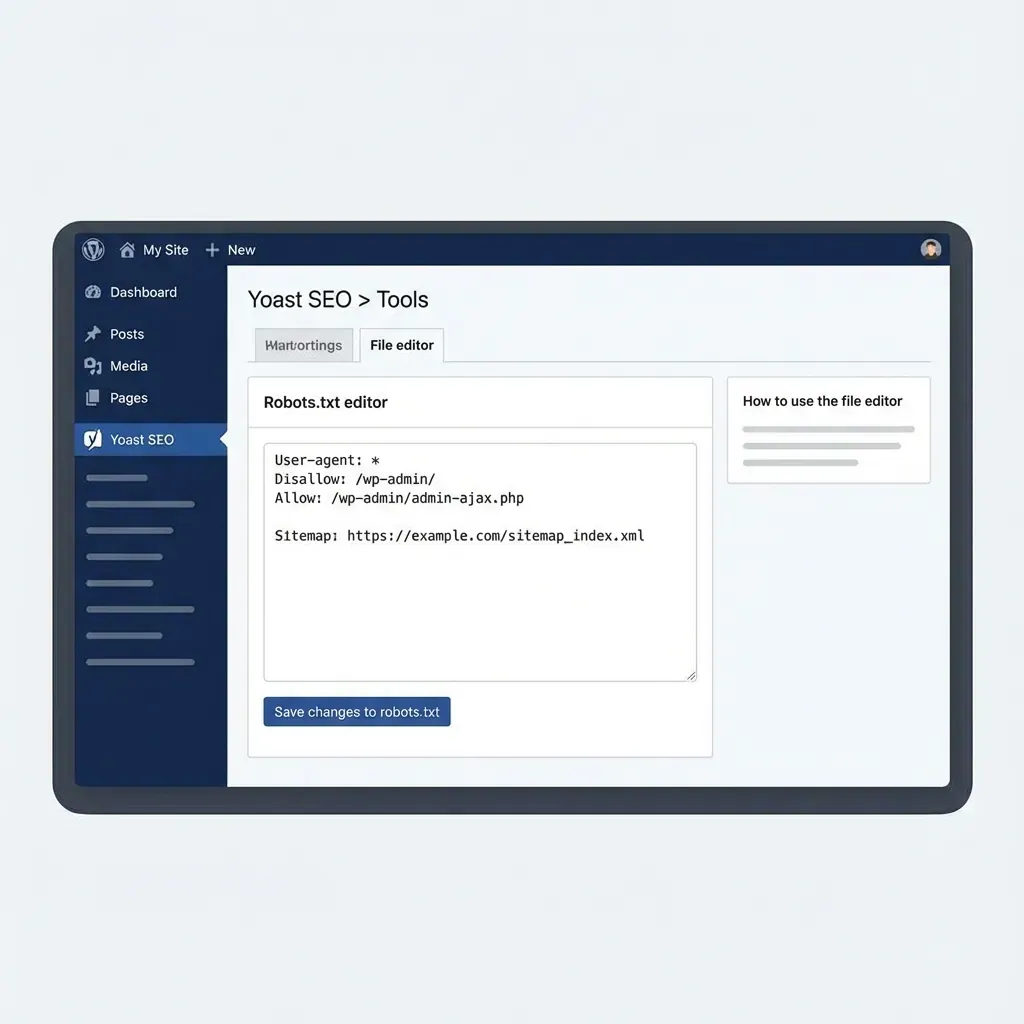
Configuración con Yoast SEO
Yoast SEO es el método más sencillo para gestionar el robots.txt en WordPress:
- Ve a SEO → Herramientas
- Haz clic en Editor de archivos
- Si no existe, pulsa Crear archivo robots.txt
- Edita el contenido y guarda los cambios
Robots.txt optimizado para WordPress (2026)
# Robots.txt optimizado para WordPress
# Generado: Enero 2026
# Sitio: tudominio.com
User-agent: *
# Directorios de administración
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# Archivos del sistema
Disallow: /wp-includes/
Disallow: /readme.html
Disallow: /xmlrpc.php
# Búsqueda interna
Disallow: /?s=
Disallow: /search/
# URLs de tracking y afiliados
Disallow: /*?utm_
Disallow: /*?ref=
# Sitemap
Sitemap: https://tudominio.com/sitemap_index.xmlErrores comunes que destruyen tu SEO
Un estudio de Search Engine Land reveló que “una gran cantidad de sitios web contienen errores en robots.txt que reducen su visibilidad hasta un 30%”.

Error 1: Bloquear todo el sitio
# ❌ INCORRECTO - Bloquea TODO el sitio
User-agent: *
Disallow: /Consecuencia: Tu web desaparece completamente de Google en 24-48 horas.
Error 2: Bloquear CSS y JavaScript
# ❌ INCORRECTO - Google no puede renderizar la página
Disallow: /wp-content/themes/Solución: Nunca bloquees archivos CSS y JS esenciales.
Error 3: Confundir rastreo con indexación
Si otros sitios enlazan a una página bloqueada en robots.txt, Google puede indexarla igualmente.
Robots.txt vs meta noindex: diferencias clave
Una confusión común es pensar que robots.txt y meta noindex hacen lo mismo. Son herramientas complementarias con funciones diferentes.
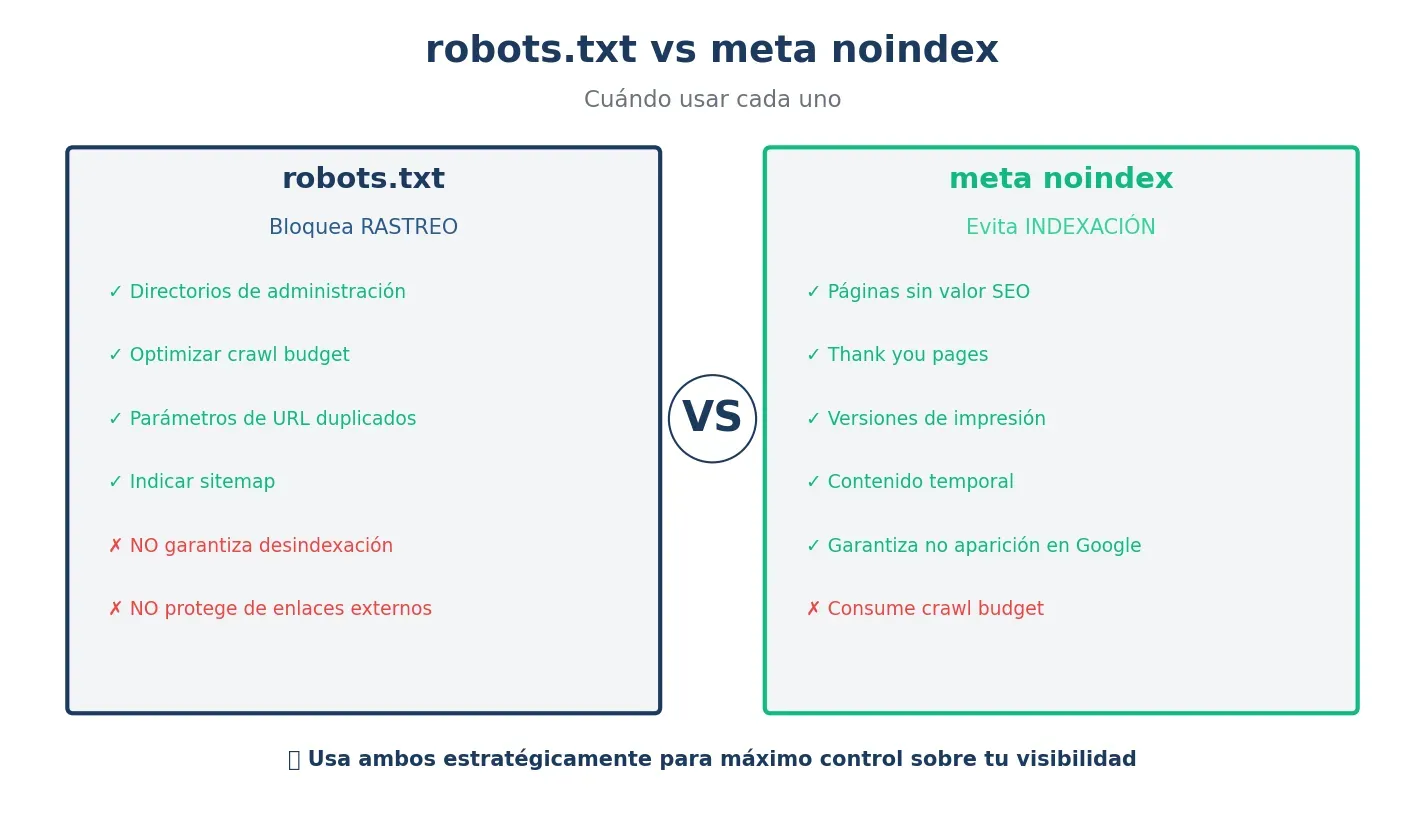
| Aspecto | Robots.txt | Meta noindex |
|---|---|---|
| Función | Bloquea el rastreo | Evita la indexación |
| Ubicación | Archivo en raíz del dominio | Etiqueta en <head> |
| Efectividad | No garantiza desindexación | Garantiza que no aparezca en resultados |
| Enlaces externos | No protege de indexación | Sí protege de indexación |
Usa robots.txt para: Bloquear directorios completos, optimizar crawl budget, bloquear parámetros. Usa meta noindex para: Páginas que no quieres en Google bajo ningún concepto (thank you pages, contenido temporal).
Gestionar bots de IA en 2025
Con el auge de ChatGPT, Claude, Perplexity y otros sistemas de IA, el robots.txt ha adquirido una nueva función: controlar si tu contenido entrena modelos de inteligencia artificial.
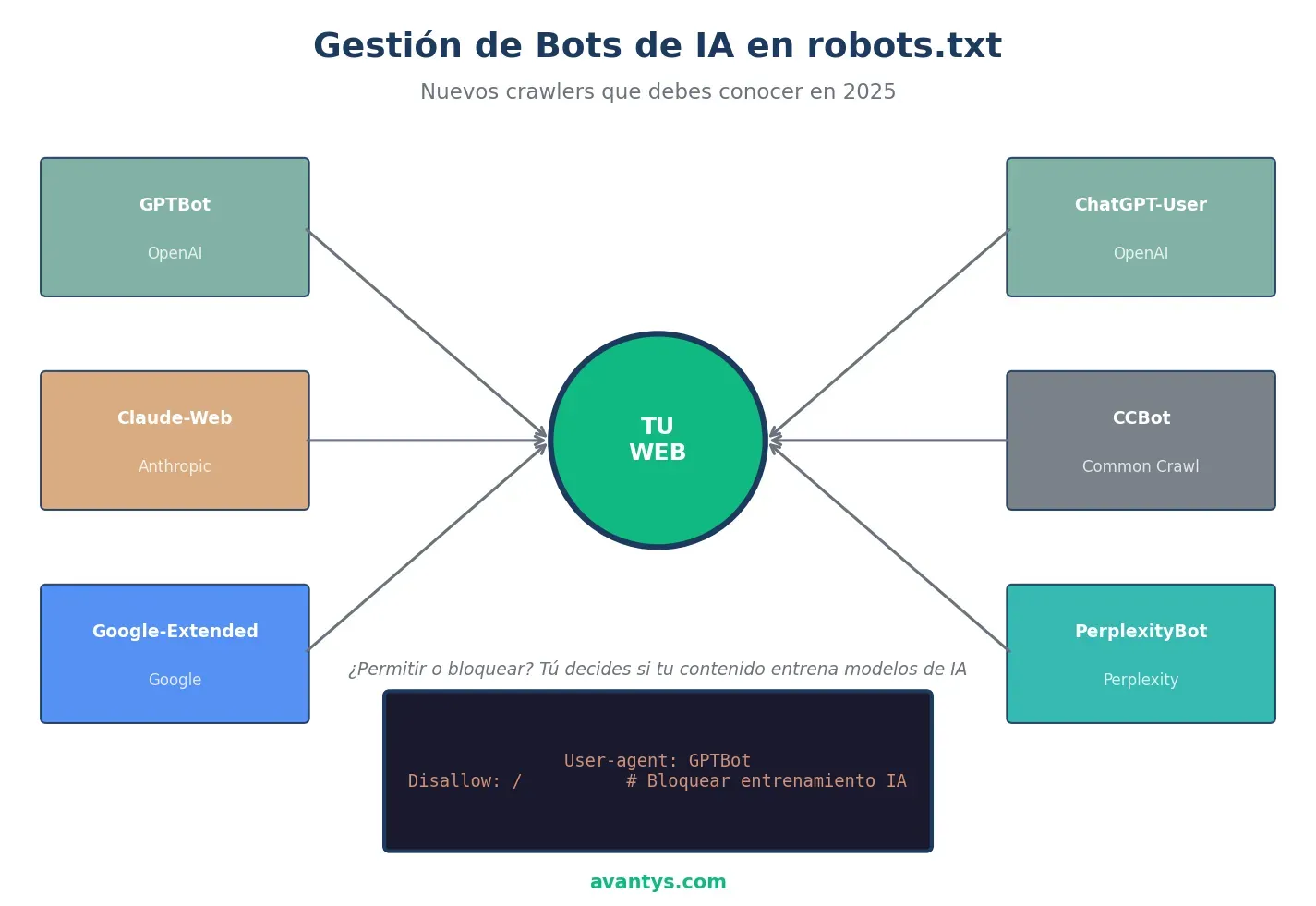
Estrategias de gestión
Bloquear todos los bots de IA
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Google-Extended
Disallow: /Argumentos para permitir bots de IA: Mayor visibilidad en respuestas de IA, citaciones y tráfico desde interfaces conversacionales. Argumentos para bloquear: Proteger propiedad intelectual, evitar que tu contenido entrene competidores.
Ejemplos prácticos por tipo de web
Tienda online (WooCommerce)
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /carrito/
Disallow: /checkout/
Disallow: /mi-cuenta/
Disallow: /*?add-to-cart=
Disallow: /*?orderby=Web corporativa
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /intranet/
Disallow: /area-privada/
Disallow: /gracias/Cómo verificar tu robots.txt
Google Search Console
- Accede a Configuración → robots.txt
- Visualiza el archivo actual y los errores detectados
Herramientas adicionales
- Screaming Frog: Auditoría completa de robots.txt.
- Merkle Robots.txt Tester: Validador online gratuito.
¿Quieres una auditoría SEO técnica profesional? Con el plan SEO para Pymes de Avantys, obtienes análisis automáticos que detectan errores en robots.txt y te guían paso a paso para solucionarlos.
Preguntas frecuentes
¿Es obligatorio tener un archivo robots.txt?
No es obligatorio. Si no existe, los motores de búsqueda asumen que pueden rastrear todo el sitio. Sin embargo, es altamente recomendable para optimizar el crawl budget y bloquear secciones innecesarias.
¿Cada cuánto debo actualizar el robots.txt?
Revisa tu robots.txt cada vez que añadas nuevas secciones a tu web, cambies la estructura de URLs o instales nuevos plugins. Como mínimo, haz una auditoría trimestral.
¿El robots.txt afecta a la seguridad de mi web?
No. El robots.txt es una sugerencia que los bots legítimos respetan, pero los bots maliciosos lo ignoran. No uses robots.txt como medida de seguridad; para proteger contenido sensible, usa autenticación.
¿Qué pasa si tengo errores de sintaxis en robots.txt?
Los crawlers pueden ignorar parcial o totalmente el archivo. Esto puede resultar en rastreo excesivo o insuficiente, afectando tu SEO. Siempre valida el archivo en Google Search Console.
¿El robots.txt funciona para subdominios?
Cada subdominio necesita su propio archivo robots.txt. Las reglas de dominio.com/robots.txt no afectan a blog.dominio.com o tienda.dominio.com.
¿Puedo usar robots.txt para desindexar páginas rápidamente?
No. Bloquear una URL en robots.txt solo impide futuros rastreos, no elimina páginas ya indexadas. Para desindexar, usa la herramienta de eliminación de URLs en Search Console junto con meta noindex.
Conclusión: el guardián silencioso de tu SEO
El robots.txt es uno de los archivos más pequeños de tu web pero con mayor impacto en tu visibilidad. Una configuración incorrecta puede hundir meses de trabajo SEO en cuestión de horas.
Recuerda: Ubicación correcta (raíz), sintaxis precisa, no confundir con noindex y validar siempre.
¿Quieres que lo hagamos por ti?
En Avantys gestionamos tu web, hosting y crecimiento digital de punta a punta. Tú a lo importante.


